
通义千问7B-基于本地知识库问答
上期,我们介绍了通义千问7B模型的微调 部署方式,但在实际使用时,很多开发者还是希望能够结合特定的行业知识来增强模型效果,这时就需要通过外接知识库,让大模型能够返回更精确的结果。
本文将介绍一下如何从魔搭社区Notebook中,一键实现本地知识库的搭建,从而增强大模型能力。
环境配置与安装
-
本文在魔搭社区的PAI-DSW环境配置下运行 (24G显存)
-
python>=3.8
使用步骤
本文在ModelScope的Notebook的环境(这里以PAI-DSW为例)配置下运行 (可以单卡运行, 显存要求20G)
服务器连接与环境准备
1、进入ModelScope首页:modelscope.cn,进入我的Notebook
2、选择GPU环境,进入PAI-DSW在线开发环境
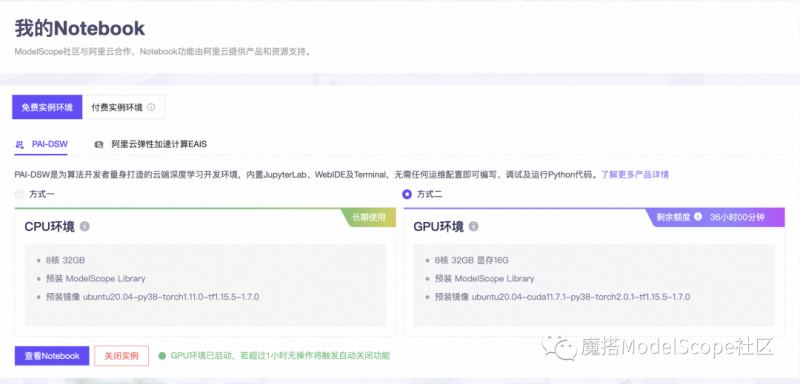
3、打开Notebook

4、将github中的最佳实践复制粘贴到notebook中
基于阿里云DashScope和Dashvector产品的通义千问7B基于本地知识库的最佳实践:
https://github.com/modelscope/modelscope/blob/master/examples/pytorch/application/qwen_doc_search_QA_based_on_dashscope.ipynb
基于开源langchain的通义千问7B基于本地知识库的最佳实践:
https://github.com/modelscope/modelscope/blob/master/examples/pytorch/application/qwen_doc_search_QA_based_on_langchain.ipynb
原理介绍
大模型利用知识库增强的逻辑的原理,是高效地将相关的信息从知识库中抽取出来并以提示词的方式送入大模型,大模型会根据相关知识以及本身生成能力输出用户想要的信息。
如何高效地从知识库中获取相关信息,采用的是目前广泛应用的基于向量搜索的方案。 向量搜索的原理是将文本转换为一串向量,并在向量数据库中以向量为索引,进行文本存储,召回的时候根据向量之间的空间距离进行相似召回,查找效率远高于传统数据库存储。
向量搜索依赖于背后向量搜索引擎,以及向量生成技术。本文中向量搜索引擎采用的是阿里云DashVector向量检索服务, 向量生成则采用的是阿里云DashScope提供的TextEmbedding API。
这里我们想要问答基于的知识库,是开源的中文突发事件语料库,通过如下建议步骤,可借助向量检索完成基于该知识库的问答:
-
将开源的中文突发事件语料库,通过TextEmbedding进行向量生成;
-
生成好的文本向量,结合原始文本一同送入DashVector向量库,并进行建库建索引,这一步为向量建索引;
-
建好索引后,如果要查找相关信息,会把需要查找的信息利用相同的向量生成方法生成向量,并通过向量引擎中的召回算法快速高效地召回相似向量,以及向量所对应的原始文本,这一步为向量召回;
-
到这一步,即完成了高效的在知识库中的查找有效信息的能力。
之后的步骤就是将召回的文本加入到提示词中喂给大模型进行后续生成。下面我们通过代码来看一下整体流程。
代码解读
本文简单介绍一下基于阿里云DashScope和Dashvector产品的通义千问7B基于本地知识库的代码逻辑:
1、申请DashScope的AK(https://help.aliyun.com/zh/dashscope/faq#D1Hxs)
2、申请Dashvector的AK(https://help.aliyun.com/document_detail/2510230.html?spm=5176.28371440.help.dexternal.6a5866d7gjWRIL)
安装依赖,下载测试知识库:
# install required packages !pip install dashvector dashscope !pip install transformers_stream_generator python-dotenv # prepare news corpus as knowledge source !git clone https://github.com/shijiebei2009/CEC-Corpus.git
对存储引擎进行初始化
import dashscope
import os
from dotenv import load_dotenv
from dashscope import TextEmbedding
from dashvector import Client, Doc
# get env variable from .env
# please make sure DASHSCOPE_KEY is defined in .env
load_dotenv()
dashscope.api_key = os.getenv('DASHSCOPE_KEY')
# initialize DashVector for embedding's indexing and searching
dashvector_client = Client(api_key='{your-dashvector-api-key}')
# define collection name
collection_name = 'news_embeddings'
# delete if already exist
dashvector_client.delete(collection_name)
# create a collection with embedding size of 1536
rsp = dashvector_client.create(collection_name, 1536)
collection = dashvector_client.get(collection_name)
def prepare_data_from_dir(path, size):
# prepare the data from a file folder in order to upsert to dashvector with a reasonable doc's size.
batch_docs = []
for file in os.listdir(path):
with open(path + '/' + file, 'r', encoding='utf-8') as f:
batch_docs.append(f.read())
if len(batch_docs) == size:
yield batch_docs[:]
batch_docs.clear()
if batch_docs:
yield batch_docs
def prepare_data_from_file(path, size):
# prepare the data from file in order to upsert to dashvector with a reasonable doc's size.
batch_docs = []
chunk_size = 12
with open(path, 'r', encoding='utf-8') as f:
doc = ''
count = 0
for line in f:
if count < chunk_size and line.strip() != '':
doc += line
count += 1
if count == chunk_size:
batch_docs.append(doc)
if len(batch_docs) == size:
yield batch_docs[:]
batch_docs.clear()
doc = ''
count = 0
if batch_docs:
yield batch_docs
def generate_embeddings(docs):
# create embeddings via DashScope's TextEmbedding model API
rsp = TextEmbedding.call(model=TextEmbedding.Models.text_embedding_v1,
input=docs)
embeddings = [record['embedding'] for record in rsp.output['embeddings']]
return embeddings if isinstance(news, list) else embeddings[0]
id = 0
dir_name = 'CEC-Corpus/raw corpus/allSourceText'
# indexing the raw docs with index to dashvector
collection = dashvector_client.get(collection_name)
# embedding api max batch size
batch_size = 4
for news in list(prepare_data_from_dir(dir_name, batch_size)):
ids = [id + i for i, _ in enumerate(news)]
id += len(news)
# generate embedding from raw docs
vectors = generate_embeddings(news)
# upsert and index
ret = collection.upsert(
[
Doc(id=str(id), vector=vector, fields={"raw": doc})
for id, doc, vector in zip(ids, news, vectors)
]
)
print(ret)
def search_relevant_context(question, topk=1, client=dashvector_client):
# query and recall the relevant information
collection = client.get(collection_name)
# recall the top k similiar results from dashvector
rsp = collection.query(generate_embeddings(question), output_fields=['raw'],
topk=topk)
return "".join([item.fields['raw'] for item in rsp.output])
初始化ModelScope上的7B千问模型
# initialize qwen 7B model
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',device_map="auto", trust_remote_code=True, fp16=True).eval()
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat",revision = 'v1.0.5', trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
# define a prompt template for the knowledge enhanced LLM generation
def answer_question(question, context):
prompt = f'''请基于```内的内容回答问题。"
```
{context}
```
我的问题是:{question}。
'''
history = None
print(prompt)
response, history = model.chat(tokenizer, prompt, history=None)
return response
# test the case without knowledge
question = '清华博士发生了什么?'
answer = answer_question(question, '')
print(f'question: {question}\n' f'answer: {answer}')
请基于```内的内容回答问题。"
```
```
我的问题是:清华博士发生了什么?。
question: 清华博士发生了什么?
answer: 抱歉,我无法理解您所说的“清华博士”指的是哪个具体的事件或情况。请您提供更详细的信息,我会尽力回答您的问题。
# test the case with knowledge
question = '清华博士发生了什么?'
context = search_relevant_context(question, topk=1)
answer = answer_question(question, context)
print(f'question: {question}\n' f'answer: {answer}')
请基于```内的内容回答问题。"
```
2006-08-26 10:41:45
8月23日上午9时40分,京沪高速公路沧州服务区附近,一辆由北向南行驶的金杯面包车撞到高速公路护栏上,车上5名清华大学博士后研究人员及1名司机受伤,被紧急送往沧州二医院抢救。截至发稿时,仍有一名张姓博士后研究人员尚未脱离危险。
```
我的问题是:清华博士发生了什么?。
question: 清华博士发生了什么?
answer: 一辆由北向南行驶的金杯面包车撞到高速公路护栏上,车上5名清华大学博士后研究人员及1名司机受伤。
以上,就是通义千问7B基于本地知识库问答的操作和演示,其中,我们使用了阿里云DashScope的免费额度和 DashVector的免费资源的相关产品。这种方法可以让各种行业的知识库与通义千问结合,给出更加精准的答案。
DashScope链接:https://dashscope.aliyun.com/
DashVector链接:https://www.aliyun.com/activity/intelligent/DashVector

