
selenium的反爬
目前针对selenium的反爬,都是从这些特征码下手的,那么该怎么反反爬呢?
- 使用火狐浏览器
大家先别急着笑,很多时候selenium 谷歌打不开目标网站,都可以用火狐试试。因为selenium只是一个控制浏览器的工具,而chromedriver和geckodriver都不是selenium官方发布的(鬼知道谁发布的),因此在控制浏览器方面会有不同的差异,具体原理不再赘述,总之很多网站不能用selenium chrome就可以试试firefox。
(理论上IE也可能会达到相应效果,但IE内核实在太烂了,selenium IE=龟速爬虫)
2. 给webdriver的options增加参数
谷歌浏览器的设置中有一个参数名为excludeSwitches,它的值是一个数组,向里面添加chrome的命令就可以在selenium打开chrome后自动执行数组内的指令,我们向里面添加一个enable-automation
from selenium import webdriver from selenium.webdriver import ChromeOptions option = ChromeOptions() option.add_experimental_option(\'excludeSwitches\', [\'enable-automation\']) brower = webdriver.Chrome(options=option) brower.get(\'file:///C:/Users/Administrator/Desktop/js.html\')
此时运行这段代码,发现可以拿到正确的信息
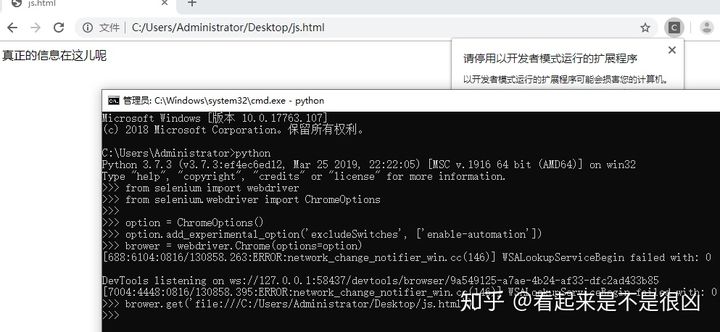
如果你觉得右上角的提示太碍眼,可以参考这篇教程禁用此提示
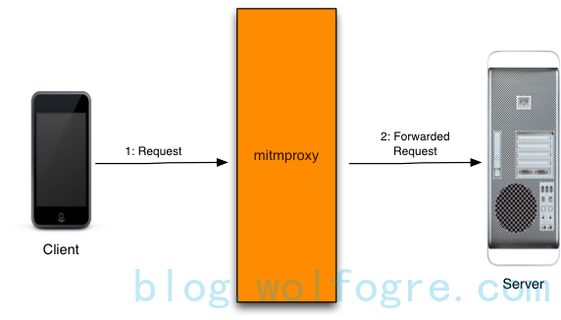
3. 中间人代理mitmproxy
爬过app的朋友应该对这玩意儿不陌生,简单介绍一下吧。mitmproxy其实和fiddler/charles等抓包工具的原理有些类似,作为一个第三方,它会把自己伪装成你的浏览器向服务器发起请求,服务器返回的response会经由它传递给你的浏览器,你可以通过编写脚本来更改这些数据的传递,从而实现对服务器的“欺骗”和对客户端的“欺骗”。具体原理和使用见此
下面提供一个防屏蔽selenium的简单demo
# my_demo.py
from mitmproxy import ctx
def response(flow):
# 'js'字符串为目标网站的相应js名
if 'js' in flow.request.url:
for i in ['webdriver', '__driver_evaluate', '__webdriver_evaluate', '__selenium_evaluate', '__fxdriver_evaluate', '__driver_unwrapped', '__webdriver_unwrapped', '__selenium_unwrapped', '__fxdriver_unwrapped', '_Selenium_IDE_Recorder', '_selenium', 'calledSelenium', '_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate', 'webdriver-evaluate', 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response', '__webdriverFunc', '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert', '__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo', '$cdc_asdjflasutopfhvcZLmcfl_']:
ctx.log.info('Remove %s from %s.' % (i, flow.request.url))
flow.response.text = flow.response.text.replace('"%s"' % (i), '"NO-SUCH-ATTR"')
flow.response.text = flow.response.text.replace('t.webdriver', 'false')
flow.response.text = flow.response.text.replace('ChromeDriver', '')
然后我们使用如下命令行启动脚本
mitmdump.exe -S my_demo.py
然后通过selenium就可以正常访问一些屏蔽selenium的网站了
4. pyppeteer
先简单介绍一下puppeteer,这玩意儿是一个基于node.js的chrome官方框架,主要用于操作谷歌无头模式进行各种操作,pyppeteer则是puppeteer的python版本。
它的作用和selenium是类似的,通过脚本操作无头谷歌,但是它并不会有selenium那么多的特征字符串,可以做到完全把“自己”当作真人操作。当然,它还是有缺点的.虽然puppeteer一直在更新,但是pyppeteer已经停止更新将近一年了,所以无法保证它以后是否可用。同样因为它是基于谷歌无头的,因此它只能用于谷歌无头,不想selenium一样,编写完脚本只需改变少量代码,便可以在多种浏览器中运行。下面是pyppeteer的官方文档:
下面是一个简单的demo
import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('file:///C:/Users/Administrator/Desktop/js.html')
print(await page.content())
asyncio.get_event_loop().run_until_complete(main())
如果你电脑中没有chromium,执行这段代码后会自动帮你安装,然后再运行这段代码,但是非常慢,所以建议自己网上下载chromium后再执行脚本
5. 编译后的chromedriver
鬼知道为什么又是chrome……最近发现的一个比较有趣的chromedriver,与一般chromedriver不同的是它经过了一些底层的修改,可以直接使用它来登录一些对selenium有检测的网站(比如某宝),有兴趣的可以私聊我获取
目前个人已知的就这几种解决方法,欢迎补充更新~
_______________________________________2020.03.11更新____________________________________
这里提供了防淘宝检测的简单demo视频版及源码(已失效),编译后的chromedriver,大家可以参考一下,编译后的chromedriver的网盘链接也在文末,大家自行获取~

